Understanding Retrieval-Augmented Generation (RAG) Systems - A Simple Guide
Intelytics.ai Team
5/8/20245 min read
In a world increasingly driven by AI, the ability to deliver precise, contextually relevant information is critical. Enter RAG, or Retrieval-Augmented Generation, a novel approach that blends the power of retrieval-based models with the generative prowess of large language models (LLMs). But why is RAG so important, and how does it stand out from traditional models? Let’s explore through a simple narrative.
The Need for RAG
Imagine you're working on a research project and need to sift through hundreds of articles to find the most relevant information. A general LLM might generate decent summaries or responses, but it lacks the specificity needed for your task. Here’s where RAG comes into play—it’s designed to retrieve exact pieces of information from vast datasets, making your research process not just easier but far more accurate.
Traditional LLMs like GPT-3 are incredibly powerful but often fall short in delivering highly specific or niche information. They rely on a fixed set of learned data, which may not cover the nuances of every query. RAG, on the other hand, combines retrieval with generation, allowing it to dynamically pull in up-to-date information, even from databases or live documents. This hybrid approach ensures that the output is both contextually relevant and accurate.
Why Use RAG?
RAG systems are better than LLMs at handling complex questions that require information from multiple sources.
They are more efficient because they focus on a smaller set of retrieved documents instead of processing everything at once.
How RAG is Better Than a General LLM Model
General LLMs generate responses based on the training data they’ve been exposed to. While they can be highly effective, they might produce outdated or incorrect information if the required context was not part of their training. RAG overcomes this limitation by fetching relevant documents from an external knowledge base before generating the response. This makes it particularly effective in scenarios where the latest or highly specific information is required.
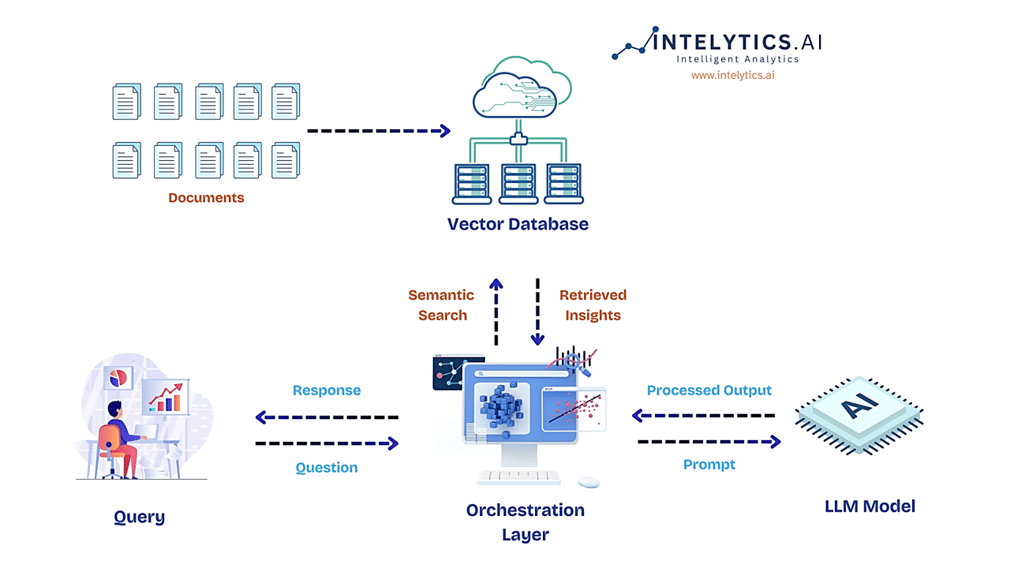
RAG Architectural Design
The image above represents the architecture model of a Retrieval-Augmented Generation (RAG) system, which combines retrieval and generation techniques for providing accurate responses.
Query:
A user starts by asking a question or making a query.
For example, a user might ask, "What are the latest advancements in AI for healthcare?"
Orchestration Layer:
This is the central component that manages the flow of information. Upon receiving the query, it determines the best way to find the most relevant information.
Example: The Orchestration Layer decides to look into a database of research papers on AI.
Semantic Search:
The Orchestration Layer then performs a Semantic Search within a Vector Database to find relevant documents. This search doesn't just match keywords but understands the context of the query.
Example: It searches for papers that discuss AI advancements in healthcare, even if the exact phrase wasn't used in the query.
Vector Database:
This database stores documents in a vector format, making them easily searchable through semantic matching.
Example: The database might contain thousands of research papers, stored in a way that allows for quick retrieval based on relevance to the query.
Retrieved Insights:
The results from the Semantic Search are then pulled out as Retrieved Insights.
Example: The system retrieves three key papers on AI's role in early disease detection.
LLM Model (Large Language Model):
The LLM receives the query along with the Retrieved Insights and generates a response.
Example: The LLM uses the retrieved papers to craft a response that summarizes the latest AI techniques being used in healthcare, such as deep learning algorithms for diagnostic imaging.
Processed Output:
The generated response from the LLM is then processed and refined to ensure clarity and relevance, known here as Processed Output.
Example: The system checks and refines the summary to make sure it’s accurate and easily understandable.
Response:
Finally, the refined response is delivered back to the user.
Example: The user receives a detailed explanation of recent AI innovations in healthcare, drawn from the most relevant and recent research.
The Role of Vector Databases in RAG
RAG systems often use vector databases to store and search the indexed documents. These databases are designed to efficiently search for similar documents based on their meaning, rather than just keywords. They store information in a format that allows for efficient similarity searches, making the retrieval process fast and accurate. Instead of traditional keyword searches, vector databases work on embeddings—mathematical representations of data—that help in identifying relevant information even when the exact keywords are not present.
RAG in action - Real-World Applications
RAG shines in situations where information is dynamic, vast, and not fully covered by the training of a model. Some scenarios where RAG is the best fit include:
Customer Support: Where responses need to be accurate and context-specific, pulling from a knowledge base of past queries, documentation, and updates.
Education: Providing students with personalized learning materials and answering their questions.
Research and Development: Where new papers or articles constantly update the knowledge base, ensuring the model delivers the latest information.
Legal Document Analysis: Where precise and contextually relevant information is critical.
End to End Solution Using RAG in Python
Let’s consider an example where RAG is used to generate answers to medical questions.
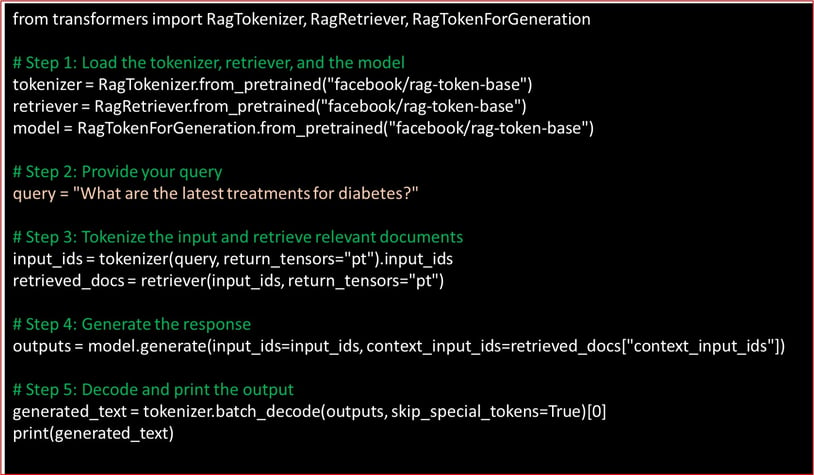
When to Use RAG
RAG systems are a good fit for tasks that require:
Finding specific information from multiple sources
Answering complex questions that require reasoning
Summarizing large amounts of information
Example: Solving a Math Problem with RAG
Imagine you need to solve a complex math problem and explain how you got the answer. A RAG system could:
Retrieve relevant math textbooks and articles from the web.
Use the LLM to analyze the retrieved documents and identify the formulas and steps needed to solve the problem.
Generate a step-by-step explanation of how to solve the problem, incorporating the information from the retrieved sources.
RAG’s Place in Industry
RAG is making significant inroads in industries that require precise, up-to-date, and contextually relevant information. From healthcare to customer service, companies are leveraging RAG to build intelligent systems that can handle complex queries with ease. In the media industry, for instance, RAG is used to generate news articles by retrieving the latest information and generating human-like text, reducing the burden on journalists.
Pros and Cons of RAG
Pros:
Accuracy: Provides more accurate information by combining retrieval with generation.
Context-Awareness: Dynamically pulls relevant data, improving context-awareness.
Flexibility: Can be adapted to various domains and industries.
Cons:
Complexity: RAG models are more complex to implement and require robust infrastructure.
Dependency on Data Quality: The quality of retrieved documents directly impacts the output.
Conclusion
RAG systems are a powerful tool that can be used to improve the performance of large language models. They are well-suited for tasks that require finding specific information, answering complex questions, and generating different creative text formats. As RAG technology continues to develop, we can expect to see it used in even more innovative ways.
Subscribe to our newsletter
Unlock Exclusive Content. Subscribe.
Intelytics.ai
Empower businesses to unlock full potential of AI.
© 2024. All rights reserved.